เมื่อจะทำ Data lakehouse ใช้ S3 หรือไปใช้ S3 table มาดูข้อแตกต่างกัน

AWS S3 table??

ในงาน AWS re:Invent 2024 ได้มีการเพิ่ม Service ขึ้นมา นั้นก็คือ S3 table ซึ่งเป็น S3 Bucket เป็นรูปแบบใหม่ในลำดับที่สาม (แต่ยังคงเป็น Preview อยู่) ซึ่งมีด้วยกันคือ
- S3 Genaral purpose
- S3 Directory
- S3 Table
โดยที่ S3 Table นั้นจะได้ความสามารถจาก S3 ปรกติครบทุกอย่างไม่ว่าจะเป็น durability, availability และ scalability เพียงแต่ว่า S3 Table นั้นถูกสร้างมาเพื่องานเกี่ยวกับการใช้ Data โดยเฉพาะ ซึ่งเปรียบเสมือนเป็น analytics warehouse ให้กับเรา โดยทาง AWS ได้พัฒนาบริการนี้ขึ้นมา เพื่อเพิ่มประสิทธิภาพในการเรียกใช้ข้อมูลไม่ว่าจะใช้กับ Redshift, Athena หรือ จะเป็น Open source อย่าง Apache Iceberg เพื่อทำ Data lakehouse เป็นต้น
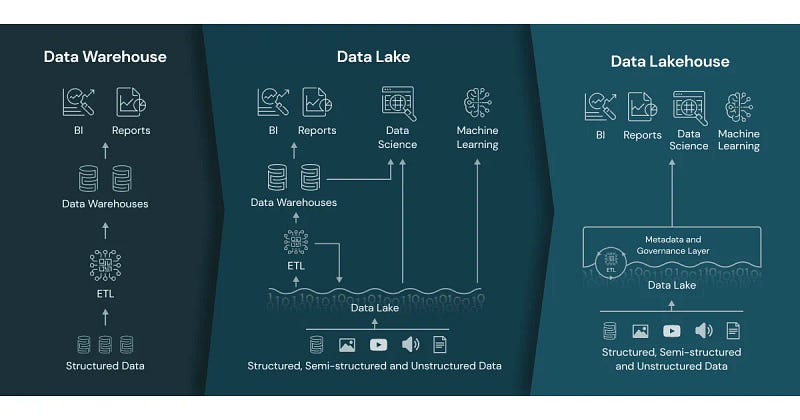
โดยทาง S3 Table รองรับการจัดการข้อมูลในรูปแบบ Tabular data และ โดยเฉพาะ Apache Iceberg format เนื่องจากปัจจุบันเจ้า Iceberg เป็นอะไรที่มาแรงมากๆในตอนนี้สำหรับ Trend Data engineer (2024)
มาลองใช้ S3 Table
โดยการที่จะใช้งาน S3 table ก็สามารถไปสร้าง Bucket ได้ที่หน้า console S3 เลยก็ได้ โดยจะมีให้เลือก S3 table
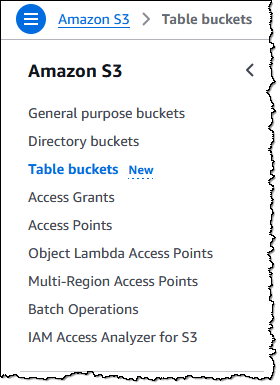
พอตอนที่เรากำลังสร้างนั้นจะมีให้เลือกเปิดการใช้งาน Integration with AWS analytics services ด้วย เพื่อเริ่มการใช้งานในการเชื่อมต่อกับ Service อื่นๆของ AWS พอเราสร้างเสร็จแล้วเราก็ได้ Bucket มา โดยตัว Bucket นี้จะไม่ได้รองกับการ Upload file โดยตรง จะใช้วิธีสร้างผ่าน UI console หรือจะเป็น CLI ก็ได้แต่ถ้าใช้ CLI ถ้าเกิดพบว่า s3tables command not found ให้ทำการ Update AWS CLI ก่อนนะครับ
aws s3tables create-table-bucket \
--region {Location} \
--name {Bucket name}
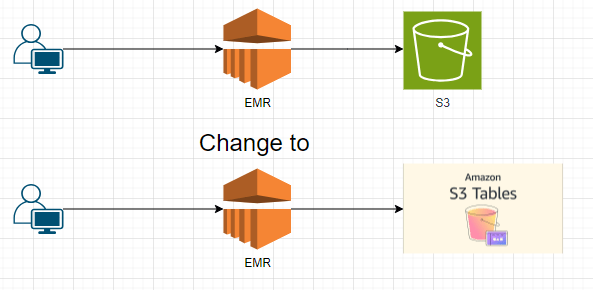
หลังจากได้สร้าง Tables bucket แล้ว โดยการจะทำการเพิ่มข้อมูลนั้นจะต้องทำผ่าน Apache Spark เท่านั้นในตอนนี้ ที่บอกได้คือตัว S3 table นั้นจะเป็นพื้นในการจัดเก็บไฟล์ที่ได้จาก Apache Iceberg, Spark เท่านั้น โดยเราจะไม่สามารถไปวางไฟล์อะไรได้เลย เป็นเพียงการเปลี่ยน Destination ของการทำ Iceberge นั้นมาลงที่ S3 table แทนที่จะไปลงที่ S3 bucket เท่านั้น เป็นการแยกออกมาจากการไปเก็บที่ S3 bucket ปรกติ
ไปกันต่อ ก่อนที่เราจะไปสร้าง Table ในนั้นทาง S3 table ได้มีการจัดการกลุ่มของข้อมูลด้วยสิ่งที่เรียกว่า Namespace (ถ้าใครเคยใช้ K8s ก็คงคุ้นๆกันบ้างหลักการคล้ายๆกันครับ) เป็นการจัดการกลุ่มก้อนข้อมูลเฉยๆ อารมณ์คล้ายๆ Dataset หรือ Schema นั้นเอง สามารถสร้างผ่านได้ทั้ง CLI และ Spark api
Namespace -> Table
# creating Namespace from CLI
aws s3tables create-namespace \
--table-bucket-arn {s3table bucket arn} \
--namespace {Namespace name}
สร้าง Apache Iceberg table ผ่าน PySpark บน EMR (Amazon Elastic MapReduce)
เราสามารถใช้เจ้า S3 tables ได้เฉพาะกับ Spark เท่านั้น แปลว่าเราจะต้องสร้าง Spark Cluster ขึ้นมาแล้วก็ทำการโยน Config เข้าไปไม่ว่าจะเป็น Package ต่างๆอะไรก็ตาม อย่างในตอนที่สร้าง EMR cluster อย่าลืมเพิ่ม Config ใน Primary node ด้วย
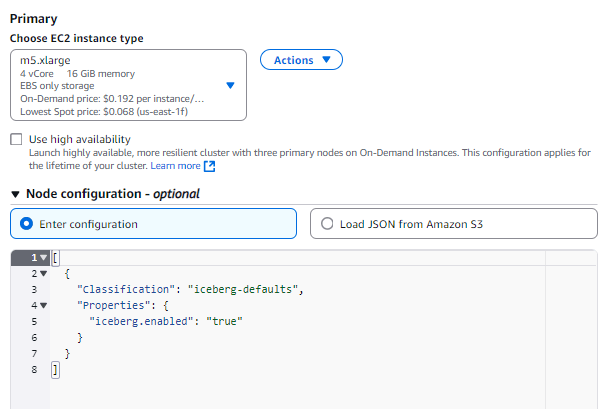
พอเราได้ Cluster มาแล้วไปทำการ SSH หรือ SSM เข้าไปที่ Primary node กันเพื่อเริ่มใช้งานเจ้าตัว Spark เพื่อที่จะได้สร้าง Table และยัดข้อมูลลงไปที่ S3tables

พอเข้ามาที่ Primary node ได้แล้วเราจะมาสร้าง Spark session แต่ก่อนจะสร้าง Spark session นั้นผมบอกก่อนว่าในบทความนี้จะใช้ Pyspark เป็นหลัก เพราะงั้นก่อนที่จะเข้าใช้งาน Pyspark ให้ใส่ — package ไปด้วย
pyspark --packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3


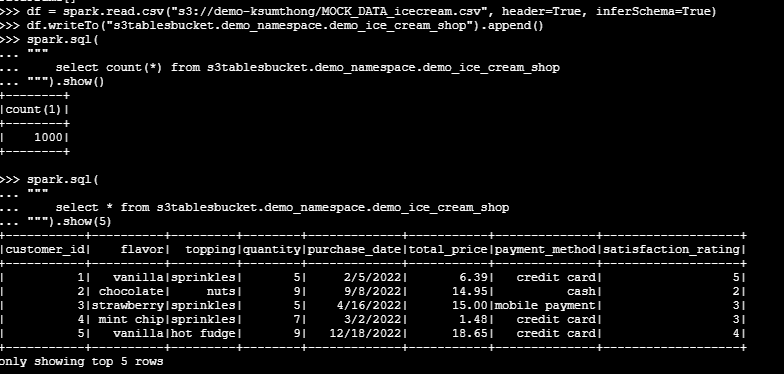
พอเริ่ม spark session ไปแล้วก็มาเริ่มสร้าง Namespace ก่อนและหลังจากนั้นก็ไปสร้าง Table ข้อมูล โดยตัวข้อมูลผมจะไปเอามาจาก file csv บน S3 แล้วก็ insert เข้าไปที่ S3tables

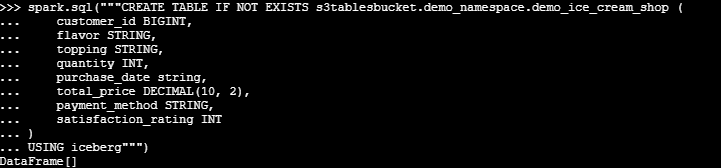
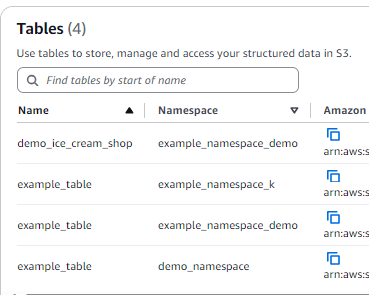
เมื่อกลับไปดูที่ S3 tables จะพบว่ามี table ได้ถูกสร้างขึ้นมาแล้ว แต่เราจะเห็นได้เท่านี้แหละไม่เหมือนกับตัว S3 ที่เวลาเราเก็บ Iceberg table เราจะเห็นทั้ง Metadata และ Parquet file
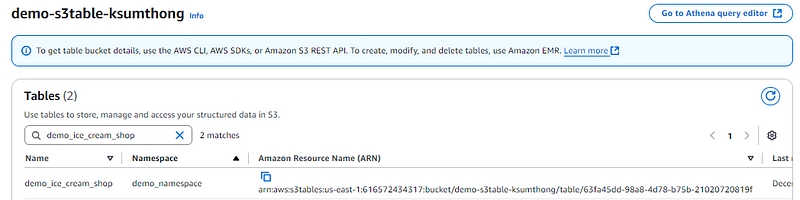
เทียบกับการเก็บ Iceberg table ใน S3 ปรกติที่จะมีทั้ง data และ metadata
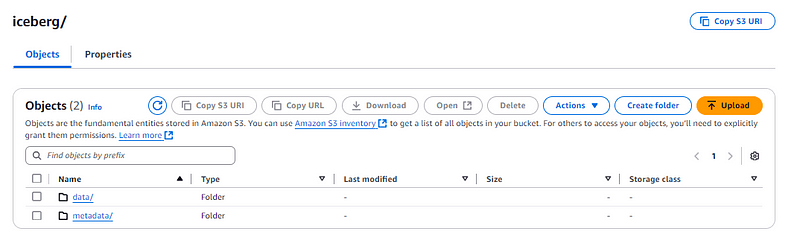
ทำการ Ingest ข้อมูลและ Read S3tables ออกมาดู เสร็จสิ้นสำหรับการเอาข้อมูลเข้า S3tables
คิดเห็นยังไงกับตัว S3tables ?
- โยน Config แล้วก็โยน Config เข้าไปในตัว Spark cluster เพราะตอนนี้ S3table ยังรองรับการทำงานร่วมกับ Spark เท่านั้น นอกจาก Config ที่เราใช้เป็นทุนเดิมอยู่แล้ว กลายเป็นว่า
- ไม่รองรับการเข้าถึง Iceberg table format กับ open source อื่นๆ ไม่ว่าจะเป็น DuckDb PyIceberg เป็นต้น ทำให้การใช้งานค่อนข้างอยู่ในวงที่แคบใช้ได้แค่เฉพาะกับ Glue Athena Redshift และ EMR เป็นต้น แต่แลกมากับ Performance ที่ทาง Official พูดไว้ว่า 3x — 10x เลย ตรงนี้ผมยังไม่ได้ทดลองเพราะ Preview ยังติดปัญหากับการ query data บน Athena อยู่
- S3tables ต้องมีความเข้าใจในการใช้งานระดับหนึ่งไม่เหมือนกับทาง S3 ปรกติที่เราจะวางไฟล์หรือทำอะไรก็ทำได้เลย
ข้อแนะนำหากอยากไปใช้ S3tables
ถ้าคุณใช้ Data platform บน AWS แบบเต็มรูปแบบกล่าวคือ ใช้ S3 เก็บข้อมูล EMR Process ข้อมูล และใช้ Redshift หรือ Athena ในการ Query data ผมคิดว่า S3table เป็นทางเลือกที่ดีเลยกับการได้มาซึ่ง Performance ที่ดีขึ้น
แต่ถ้าคุณยังต้องการใช้ข้อมูลกับ Open source ต่างๆไม่แนะนำเลยครับในตอนนี้ซึ่งในอนาคตอาจจะทำได้ก็ได้หลังจากหมด Preview ไปแล้ว
ตอนนี้อาจจะยังทดสอบไม่ได้เยอะเนื่องจากยัง Preview อยู่เอาไว้หลังจาก General available จะกลับมาทดสอบกันครับ
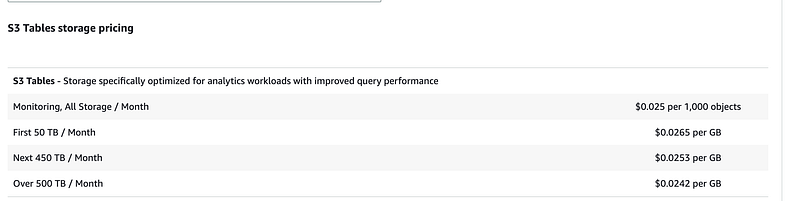
เรื่อง Cost นั้น บนตัว S3tables

S3 standard


จะเห็นได้ว่าราคาของ S3tables จะแพงกว่ากัน นิดหน่อย ถ้าเรามีข้อมูลสัก 10 TB
- S3tables จะจ่าย 265 USD
- S3 standard จะจ่ายที่ 230 USD
Follow me here!
Linkedin:
https://www.linkedin.com/in/kriangsak-sumthong/
Facebook page:
https://www.facebook.com/profile.php?id=61563097228247
Medium:
https://medium.com/@puk.kriangsak

Leave a comment