Auto-copy ข้อมูลจาก S3 มาที่ Redshift, GA แล้วใช้งานยังไง🚀

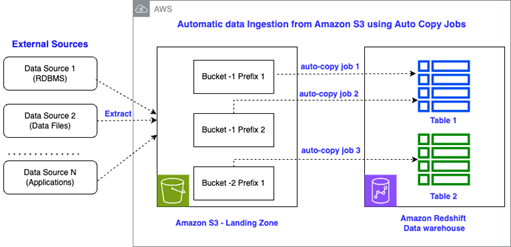
S3 triggered base data ingestion
บางครั้งในงาน Data engineer เราก็ไม่ได้อยากที่จะใช้ Pipeline เต็มรูปแบบ เพราะบางครั้ง Data ที่ได้มานั้นก็ถูก export มาสมบูรณ์ แล้วเช่นเป็นการ export จาก ระบบ ERP หรือ 3rd party data warehouse ทำให้เราไม่ได้อยากที่จะใช้วิธีการ ETL สักเท่าไหร่ ขอแค่ให้ข้อมูลเข้าไปเก็บอยู่ที่ Data warehouse ก็พอ อย่างตัว AWS Redshift
ทีนี้ถ้าเป็นก่อนหน้านี้การจะทำแบบนั้นได้เราอาจจะต้องมีการเรียกใช้ Lambda เอย หรือ Event bridge, SNS ในการทำ triggered base data pipeline ก็ได้ เช่นตัวอย่าง Diagrams


Make a shortcut!
ด้วยการที่จะทำ Data ingestion ง่ายๆนั้น กลับต้องทำผ่านหลายๆ Service ทำให้การทำงานนั้นมีขั้นตอนเพิ่มขึ้น การจัดการก็มากขึ้นตามไปด้วย ไม่ว่าจะเป็น Code ที่ต้องเขียน configurations ที่ต้องใส่อีก เลยอยากชวนมาใช้ S3 event integrations กัน
S3 event integrations คือการที่เวลามี Event ที่ S3 เช่น ไฟล์ข้อมูลเกิดการเปลี่ยนแปลง อัพโหลดไฟล์ใหม่ เป็นต้น โดยที่ S3 จะส่ง Event ไปที่ Redshift โดยตรง ทำให้เราสามารถเขียน Auto – copy ได้นั้นเอง
Prerequisites
- Redshift Provision cluster หรือ Redshift serverless workgroup
- S3 bucket
Let’s try it out
S3 bucket policy
อย่างแรกเลยเราจำเป็นต้องเพิ่ม Bucket policy ก่อนที่ S3 โดยไปที่ Bucket ที่เราต้องการแล้วเลือกไปที่
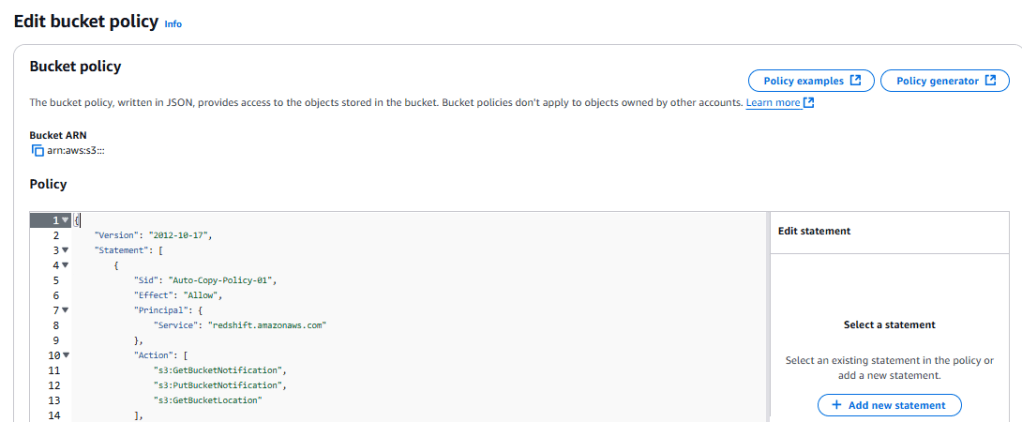
แล้วใส่ Bucket policy ประมาณนี้ ค่าต่างๆก็จะเป็น Bucket ARN และก็ Redshift ARN
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Auto-Copy-Policy-01",
"Effect": "Allow",
"Principal": {
"Service":"redshift.amazonaws.com"
},
"Action": [
"s3:GetBucketNotification",
"s3:PutBucketNotification",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::<<your-s3-bucket-name>>",
"Condition": {
"StringLike": {
"aws:SourceArn": "arn:aws:redshift:<region-name>:<aws-account-id>:integration:*",
"aws:SourceAccount": "<aws-account-id>"
}
}
}
]
}
พอเราพร้อมแล้วก็ไป Set up ต่อที่ Redshift กัน
Redshift: S3 event integration
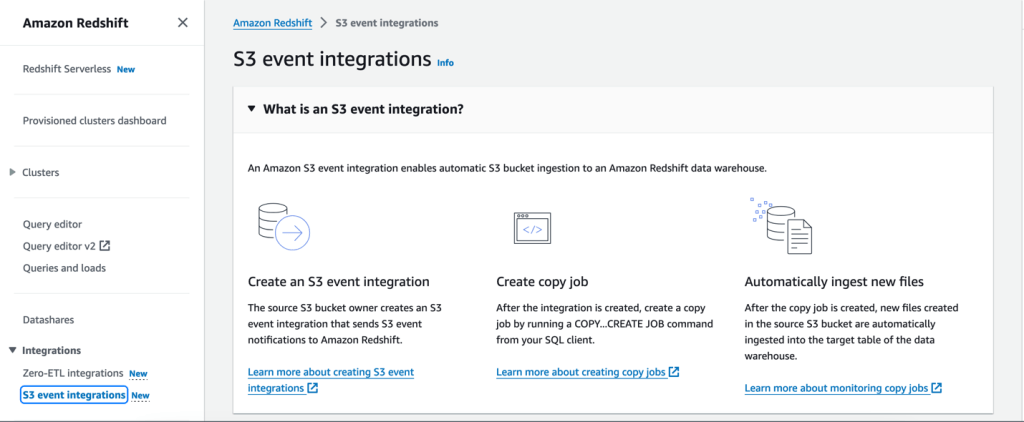
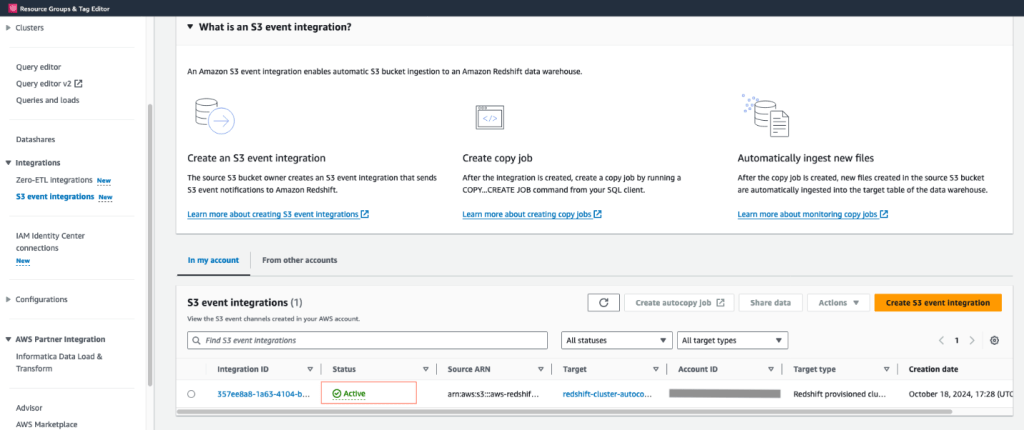
ถ้าเข้ามาที่ Redshift ก็จะเจอคำว่า S3 event integration ก็กดไปได้เลยมาตั้งค่ากัน เพื่อให้ทั้งสอง S3 และ Redshift ได้มีการเชื่อมต่อกัน


ถ้าในขั้นตอน Select target แล้วเจอ Error ไม่ต้องตกใจให้เลือก
Fix it for me ไปเลยเป็นเพิ่ม Policy ที่ Redshift

พอเราได้ตั้งค่าเลือกหมดทุกอย่างแล้วก็จะได้ S3 integration มาแล้ว✨
Set up auto-copy jobs
หลังจากที่เราได้ setup ทั้ง policy และ S3 integration แล้ว ที่เหลือก็เป็นเพียงการสร้าง Auto-copy job ใน Query editor ซึ่งคำสั่งที่เราจะใช้เป็น Copy syntax แต่าถ้าใครยังงงเมื่อได้อ่านแล้วก็ไม่เป็นไร ผมก็งงในตอนแรก😅 มาดูกันว่าต้องเขียนยังไง
ตัวอย่าง syntax ก็ประมาณนี้
COPY <table-name>
FROM 's3://<s3-object-path>'
[COPY PARAMETERS...]
JOB CREATE <job-name> [AUTO ON | OFF];
-- example load csv file to table with ',' as delimiter and
-- skip column name
COPY "database"."schema"."target_table_name"
FROM 's3://<bucket-name>/<prefix-path>'
IAM_ROLE 'arn:aws:iam::<<iam role>>'
DELIMITER ','
IGNOREHEADER 1
JOB CREATE <<job name>>
AUTO ON;แต่!! ก่อนที่ auto-copy ได้ต้องมี table รองรับการนำเข้าข้อมูลก่อนนะครับ เช่น
CREATE TABLE public.target_table (
id int not null,
first_name text not null,
last_name text not null
);เท่านี้ก็สามารถสร้าง Auto-copy ได้แล้วเพียงแค่เอาไฟล์ไปเก็บที่ S3 path ที่เราได้กำหนดไว้ เพียงเท่านี้ Data ก็จะถูกเก็บตามที่เรากำหนดแล้ว
Monitoring and Check copy job
- If data does not loads into table: ในกรณีที่เราเอาไฟล์ไปเก็บที่ S3 แล้วไม่มีข้อมูลที่ Redshift ให้ลองใช้ Query นี้ดูเพื่อเช็คว่าเกิดอะไรกับ Job หรือเปล่าจะได้แก้ไขได้
SELECT query_id,
table_id,
start_time,
trim(file_name) AS file_name,
trim(column_name) AS column_name,
trim(column_type) AS column_type,
trim(error_message) AS error_message
FROM sys_load_error_detail
ORDER BY start_time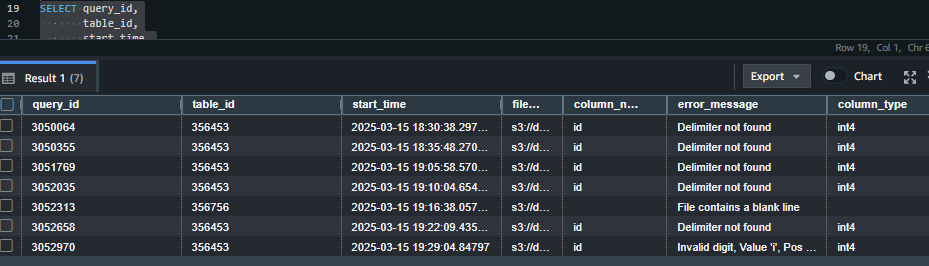
- Checking what job you have: ถ้าอยากเช็คว่ามี Auto-copy job อะไรบ้าง
-- Check current job list
select * from SYS_COPY_JOB
-- Manually run a auto-copy job
copy job RUN <<auto-copy job Name>>
-- Drop (delete) job
COPY JOB DROP <<Job name>>Difference between Copy and Auto-copy job
| <> | Copy | Auto-copy job |
| Syntax | COPY FROM ‘s3://’ [COPY PARAMETERS…] | COPY FROM ‘s3://’ [COPY PARAMETERS…] JOB CREATE ; |
| Data Duplication | If it is run multiple times against the same S3 folder, it will load the data again, resulting in data duplication. | It will not load the same file twice, preventing data duplication. |
Benefits and consideration
Benefits
- Auto-job ช่วยให้เราสามารถ Automate งานที่สั้นๆง่ายอย่างการเอาไฟล์เข้า Redshift ตรงๆได้เลย
- Auto-job จะมีการเก็บข้อมูลที่เคย Load ไปแล้วทำให้การ Load ข้อมูลนั้นจะมีการซ้ำของข้อมูลน้อยลงไป
- Function นี้ฟรีโดยไม่มีค่าใช้จ่าย
consideration
- ด้วยความที่ถ้าเรามีไฟล์เก่าอยู่แล้ว แล้วจะเพิ่มข้อมูลจะต้องใช้คำสั่ง Copy แทน
- คำสั่งพวกนี้ยังไม่รองรับ MAXERROR parameter, manifest files และ key-based access control
เป็นไงบ้างครับสำหรับการเอาข้อมูลเข้าไปที่ Redshift โดยตรงไม่ต้องผ่านอะไรเลยทำให้ลดการสร้าง Pipeline ที่ยุ่งยากออกไป แต่ก็คำนึงถึงว่าเราจะต้องมีการทำ ETL ก่อนหรือถ้าไม่ก็ Auto-copy กันดีกว่า✨🚀

No need to manual things!

Leave a comment