Apache Iceberg บน BigQuery ไม่ได้จำเป็นต้องทำผ่าน Biglake อย่างเดียวแล้ว

Lakehouse is everywhere!
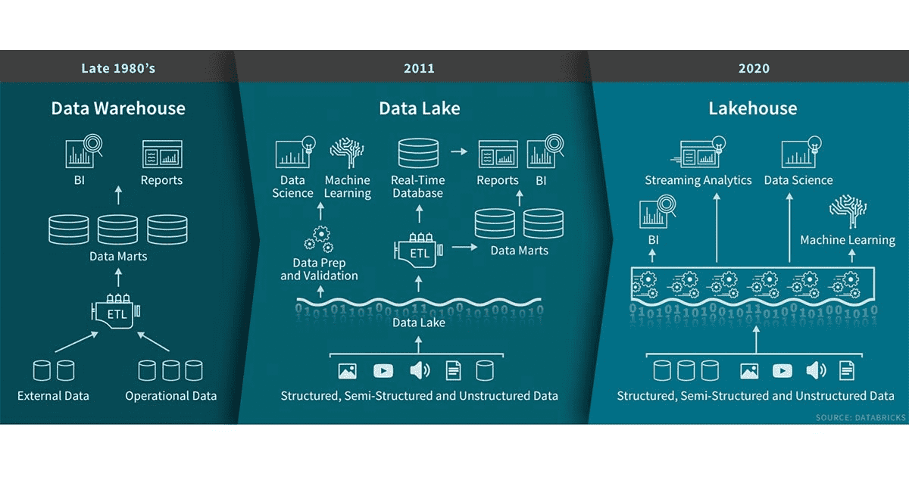
อย่างที่รู้ตอนนี้การทำ Data architecture ที่เป็นนิยมอย่างแพร่หลายก็คงไม่พ้นรูปแบบ Data Lakehouse ใครที่เข้ามาอ่านแล้วงงว่า Data lakehouse คืออะไรก็ดูรูปตามนี้ได้เลยอธิบายแบบรวบรัด
Apache Iceberg
โดยการที่จะจัดทำ Data lakehouse ได้นั้นสิ่งที่สำคัญคือการที่เราสามารถจัดการข้อมูลได้เลยบน Data lake และการที่จะทำยังงั้นได้เราต้องมี Service หรือ Tool อะไรบางอย่าง โดยสิ่งที่เขียนถึงในบทความก็คือ Apache Iceberg ที่เป็น Open source table format ต้องบอกก่อนว่าในโลกของ Data lakehouse ไม่ได้มีแค่ Iceberg แต่ยังมีอื่นๆอีก
ศึกษาเพิ่มเติมเกี่ยวกับ Apache Iceberg แนะนำ: https://www.dremio.com/resources/guides/apache-iceberg-an-architectural-look-under-the-covers/
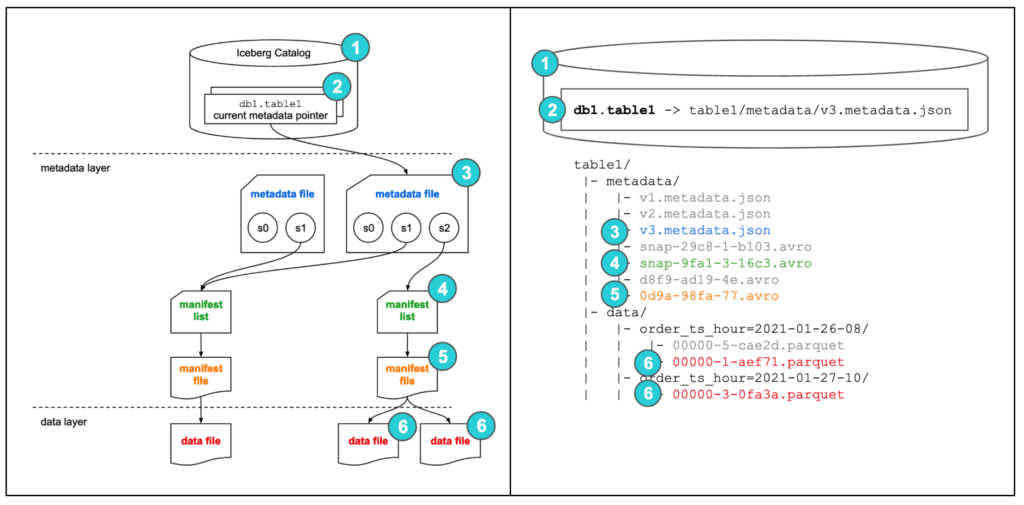
Bigquery กับการใช้งานร่วม Apache Iceberg
การที่เราอยากจะเอา Iceberg มาใช้งานกับ Bigquery นั้นสามารถทำได้หลายวิธีโดยอย่างการสร้าง Iceberg ผ่าน Spark แล้วก็ใช้ Biglake ในการทำ External table เพื่อที่จะสามารถนำมา Query ผ่าน Bigquery ได้
แต่ตอนนี้ทาง GCP ได้เพิ่มวิธีมาอีกสองวิธีนั้นก็คือ BigQuery metastore และ BigQuery tables for Apache Iceberg โดยเราจะมาลองใช้งานกันดูแต่ขอบอกก่อนนะครับ บางอย่างยังอยู่ในหมวด Preview นะครับเพราะฉะนั้นอาจจะมีการเปลี่ยนได้เสมอ
โดยประโยชน์หลักๆทำไมเราจะต้องมาใช้ Metastore กับทาง Google cloud นั้นก็เพื่อเราจะสามารถควบคุมสิทธิ์ หรือ Data gorvernance ได้สะดวกยิ่งขึ้น โดยเฉพาะเมื่อเราอยากจะใช้งาน Data warehosue ที่ทรงประสิทธิ์ภาพอย่าง Bigquery นั้นเอง

โดยเราจะมาสร้าง Iceberg table ผ่านทั้งสามอย่างทั้ง
- BigLake external tables for Apache Iceberg
- BigQuery metastore Iceberg tables
- BigQuery tables for Apache Iceberg
โดย Tool หลักก็คือ Dataproc เพราะเราจะต้องใช้งาน Spark นั้นเองโดยเราจะมาทำการสร้าง Iceberg table ผ่าน Dataproc ไปด้วยกัน 😁
Metastore คืออะไร? เพราะในบทความนี้เราจะเจอคำนี้บ่อยมาก
Metastore คือส่วนประกอบที่เก็บข้อมูลส่วนที่สำคัญเกี่ยวกับ Metadata, schema, ชื่อ table, ที่อยู่ของไฟล์ในกรณี Lakehouse และ ข้อมูล Partition เป็นต้น ในส่วนของ Metastore ที่เป็น Open source นั้นก็มี Apache Hive หรือ Unity อื่นๆอีก
แต่ในบทความจะเขียนแค่ที่เกี่ยวกับ Google cloud นะครับ
Biglake for Apache Iceberg
การสร้าง Table ผ่าน Biglake for Apache Iceberg นั้นสามารถทำได้สองขั้นตอนใหญ่
- สร้าง table ผ่าน Biglake metastore ใน Spark cluster (Dataproc)
- สร้าง External table with Iceberg metadata file ที่ Bigquery
เริ่มกันเลย step ในการทำก็มีดังนี้
- โดยหลังจากได้สร้าง Dataproc แล้วให้ SSH เพื่อเข้าไปใช้งานในส่วนของ spark กัน
- พอเข้ามาใน Terminal แล้ว ก็มาเข้าขั้นตอน เปิด spark session และเป็นการเพิ่ม Spark packages เข้าไปด้วย ใช้คำสั่งประมาณด้านล่างนี้
spark-sql \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.13:1.9.0 \
--jars gs://spark-lib/biglake/biglake-catalog-iceberg1.5.1-0.1.2-with-dependencies.jar \
--conf spark.sql.catalog.{catalogname}=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.{catalogname}.catalog-impl=org.apache.iceberg.gcp.biglake.BigLakeCatalog \
--conf spark.sql.catalog.{catalogname}.gcp_project={Project ID} \
--conf spark.sql.catalog.{catalogname}.gcp_location={Region} \
--conf spark.sql.catalog.{catalogname}.warehouse=gs://{gcs path}- หลังจากทาง spark ได้ทำ Download และ Config แล้ว เราจะได้ spark sql มาใช้งาน แล้วก็เริ่มจากการเปลี่ยน Catalog และสร้าง Namespace กัน ({catalogname} = biglake_catalog)
-- change default catalog
USE biglake_catalog;
-- create namespace (as same as dataset)
CREATE NAMESPACE demo;
-- change to demo namespace
USE demo;
- หลังจากได้ USE demo ไปแล้วก็มาสร้าง table แล้ว insert ข้อมูลกัน
-- create new table
CREATE TABLE customer (
id INT,
name STRING,
age INT
) USING iceberg;
-- insert data to new table
INSERT INTO customer VALUES
(1, 'Alice', 30),
(2, 'Bob', 24),
(3, 'Charlie', 35),
(4, 'David', 28),
(5, 'Eve', 42),
(6, 'Frank', 29);
-- query data to check if it success or not
SELECT * FROM customer;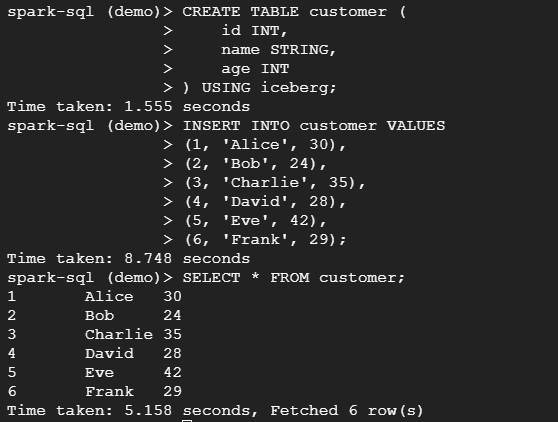
- จากที่เราได้ทดสอบดูข้อมูลแล้วปรากฏว่ามีข้อมูลที่เป็นไปตามที่เราต้องการแล้วอยู่ในรูปแบบ Iceberg table ทีนี้ลองไปเช็คที่ GCS กันว่าได้มีไฟล์ไหม

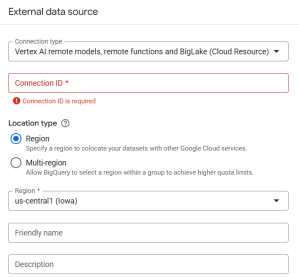
- มีข้อมูลแล้วที่ GCS แต่ทีนี้ถ้าไปดูที่ Bigquery เราจะไม่เห็นข้อมูลเลยนั้นเป็นเพราะการใช้ Biglake metastore นั้นเราจะต้องทำการ สร้าง External table ขึ้นมาเอง โดยเริ่มจากสร้าง Biglake connection ก่อน ไปที่ +Add data บน Bigquery แล้วค้นหาคำว่า Biglake

- ให้เลือกไปที่ Vertex AI แล้วก็เลือก ชื่อที่ต้องการ และ Region ให้เรียบร้อย
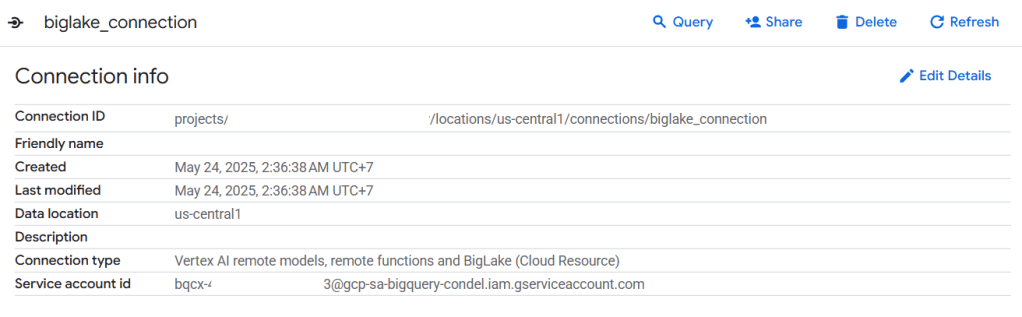
- พอสร้างเสร็จแล้วเราจะได้ Connection มาอยู่ใน External connections ให้นำ Service account ไปเพิ่ม Role ใน IAM

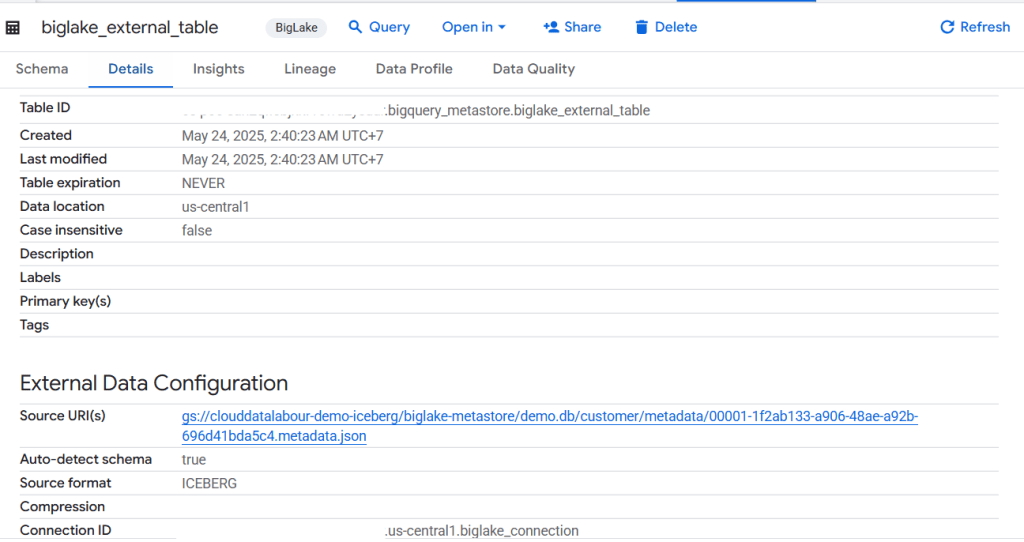
- มาสร้าง External table กัน โดยมีตัวอย่างรูปถัดไป โดย URI ของจะเป็นที่ๆของ Metadata json file ที่ได้เราสร้าง Table เอาไว้
CREATE EXTERNAL TABLE myexternal-table
WITH CONNECTION `myproject.us.myconnection`
OPTIONS (
format = 'ICEBERG',
uris = ["gs://mybucket/mydata/mytable/metadata/iceberg.metadata.json"]
)
เป็นอันเสร็จสิ้นเราก็ได้ Table มาอยู่ที่ Bigquery แล้ว 🚀
BigQuery metastore Iceberg tables
ส่วนนี้คือการที่เราจะมาใช้ Bigquery มาเป็น Metastore กัน โดยตัว Bigquery metastore นั้นจะช่วยให้เราไม่ต้องมาสร้าง External table เองให้เหมือนกับ Biglake metastore และเมื่อไหร่ก็ตามที่เราได้สร้าง Table ผ่าน Bigquery metastore เราจะเห็นข้อมูลทั้งบน GCS เหมือนเวลาที่เราสร้าง Iceberg table แบบทั่วไป และ ก็จะมี table ให้เห็นใน Bigquery ด้วย
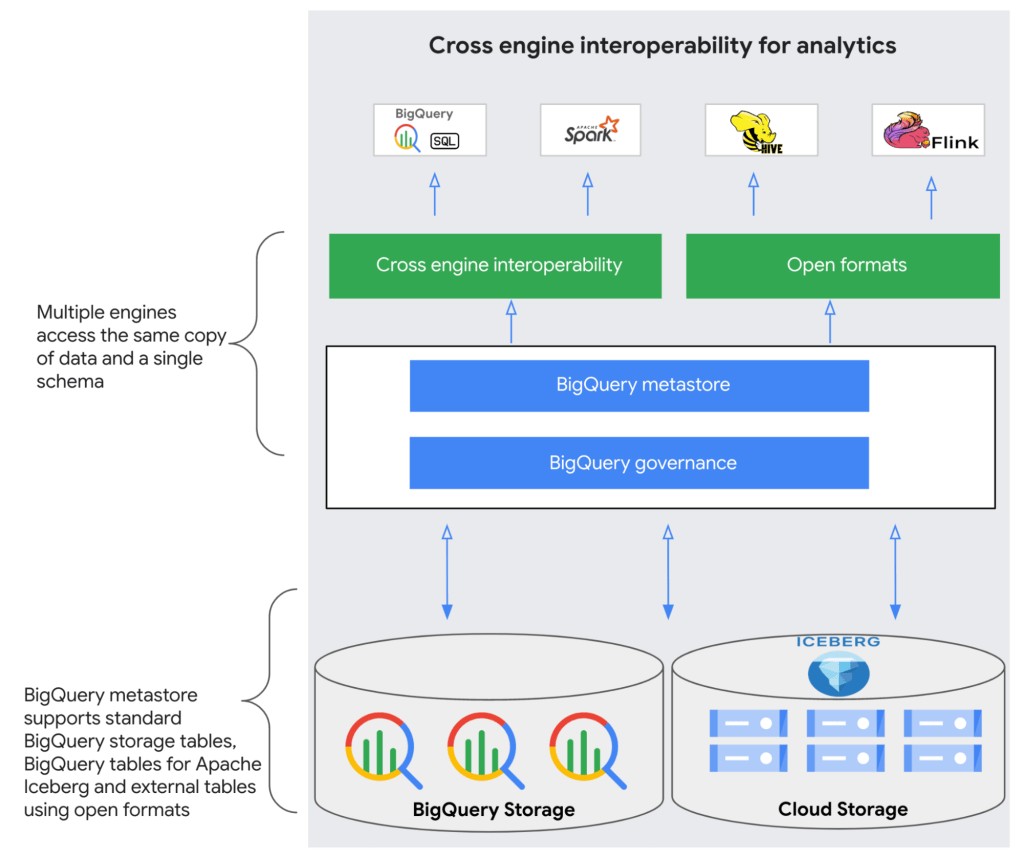
มาดูส่วนของการใช้งานแบบง่ายๆกันผ่าน Dataproc CLI
- เริ่มต้นก็เป็นการ SSH เข้า Dataproc cluster ถ้ายังไม่ได้สร้างก็สร้าง cluster ได้เลยครับ
- พอเข้าสู่หน้าต่าง terminal ได้แล้วก็มาเริ่มขั้นตอนสร้าง spark session และ กำหนดค่า config ต่างๆไปด้วย เช่น catalog name, project id และ warehouse (GCS)
spark-sql \
--jars "https://storage-download.googleapis.com/maven-central/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,gs://spark-lib/bigquery/iceberg-bigquery-catalog-1.6.1-1.0.1-beta.jar" \
--conf "spark.sql.catalog.{catalogname}=org.apache.iceberg.spark.SparkCatalog" \
--conf "spark.sql.catalog.{catalogname}.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" \
--conf "spark.sql.catalog.{catalogname}.gcp_project={project id}" \
--conf "spark.sql.catalog.{catalogname}.gcp_location={location}" \
--conf "spark.sql.catalog.{catalogname}.warehouse=gs://{gcs path}"- ต่อมาก็จะเป็นการสร้าง Namespace และ Table แล้วก็ Insert ข้อมูลเข้าไปใน Table กัน ป้อนคำสั่งทีละคำสั่งนะครับถ้าจะทำตาม โดยในตัวอย่างผมจะจะตั้งค่าให้ {catalogname} = bq_catalog นะครับ
# use catalog where we set up on spark-sql, eg. bq_catalog
USE bq_catalog;
# create namespace in this example we use "demo"
CREATE NAMESPACE IF NOT EXISTS demo;
# use namespace
USE demo;
# create table
CREATE TABLE bq_catalog.demo.customer (
id INT,
name STRING,
age INT
) USING iceberg;
# insert value
INSERT INTO bq_catalog.demo.customer VALUES
(1, 'Alice', 30),
(2, 'Bob', 24),
(3, 'Charlie', 35),
(4, 'David', 28),
(5, 'Eve', 42),
(6, 'Frank', 29);
# to check metadata of the table
DESCRIBE EXTENDED bq_catalog.demo.customer;
# to show list of table inside namespace
SHOW TABLES;- ถ้าเราได้ทำตามขั้นตอนไปแล้วเราจะได้เห็น table ใน Bigquery โดยที่จะมี Dataset ชื่อเดียวกับ namespace ที่เราได้ตั้งชื่อเอาไว้ และก็จะมีไฟล์ข้อมูลอยู่ใน GCS ด้วย
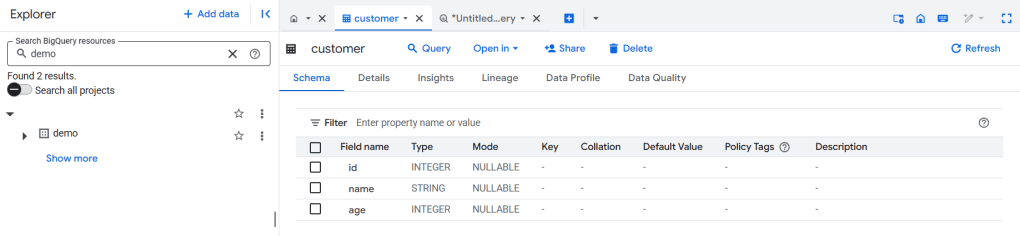
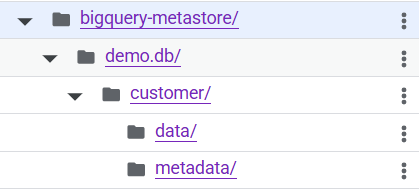
อย่างที่บอกว่าพอเราใช้ Bigquery metastore เราจะไม่สามารถเขียน DML (data manipulate) ได้เช่น Insert update ก็อย่างที่จะได้เห็นทาง Bigquery จะ show error มาเลย

BigQuery tables for Apache Iceberg
สำหรับ Bigquery table for Apache Iceberg จะต่างตรงที่เราจะสามารถสร้าง Iceberg table บน Bigquery ได้เลยโดยที่ไม่ต้องไปเปิด spark cluster อะไร
เหมาะกับการที่เราต้องการใช้งาน DML (Data minipulate) บน Bigquery พูดง่ายๆก็คือไม่จำเป็นจะต้องอ่านได้อย่างเดียวบน Bigquery แต่เราสามารถเขียนทับไปได้ด้วย และอีกข้อคือเราก็จะมี Iceberg table file ด้วยที่ GCS ทำให้เราสามารถนำไปใช้งานต่อที่อื่นได้ แต่จะไม่สามารถเชื่อมต่อ Bigquery Metastore กันได้แค่นั้นเอง
ส่วนไฟล์ที่เกิดขึ้นที่ GCS นั้นเราก็สามารถนำไปเชื่อมต่อกับ Open source อื่นๆได้อย่างพวก DuckDB อะไรแบบนี้

มาดูตัวอย่างการสร้าง Iceberg table กันเลย โดยเราจะใช้แค่ Bigquery เท่านั้นเองไม่ต้องมี Spark cluster
เราจะมาสร้าง customer table เหมือนกับทาง Bigquery metastore กันเลย
# create Iceberg table
CREATE TABLE `project_id.dataset_id.customer` (
id INT,
name STRING,
age INT
)
CLUSTER BY id
WITH CONNECTION DEFAULT
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://path/warehouse/tablename');
# insert data into table
INSERT INTO `project_id.dataset_id.customer` VALUES
(1, 'Alice', 30),
(2, 'Bob', 24),
(3, 'Charlie', 35),
(4, 'David', 28),
(5, 'Eve', 42),
(6, 'Frank', 29);เพียงเท่านี้เราก็จะได้ Bigquery Iceberg table มาแล้วจะเห็นได้ว่าเราสามารถ Insert ข้อมูลได้ไม่เหมือนกับ Metastore ที่เราเขียนไปก่อนหน้า
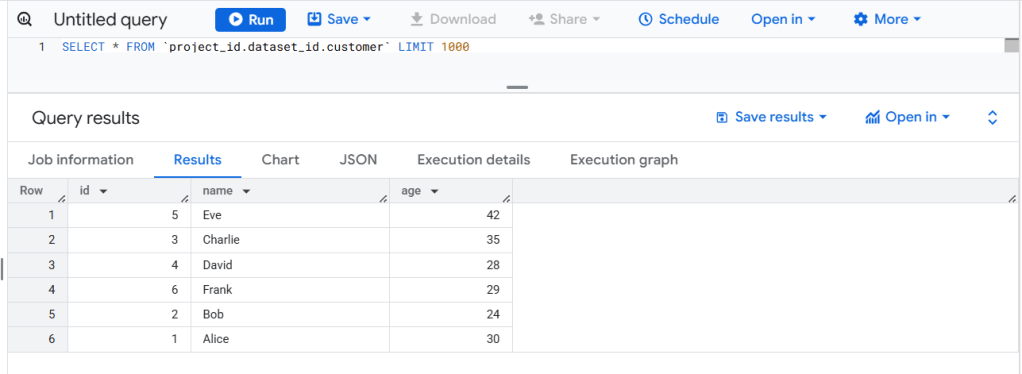
เราสามารถสร้าง Iceberg table ได้จาก query result เช่นกัน
CREATE TABLE `project_id.dataset_id.customer2` (
id INT,
name STRING,
age INT
)
CLUSTER BY id
WITH CONNECTION DEFAULT
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://path/warehouse/tablename')
AS
(select * from `project_id.dataset_id.customer`);มาดู GCS กันบ้างว่าเราได้มีไฟล์

มีไฟล์เกิดขึ้นมาจริงๆด้วย เป็นเสร็จสมบูรณ์ 😁😁
Summary
หลังจากเรารู้ว่าเราสามารถเชื่อมต่อ Iceberg กับ Bigquery ได้หลายทางแล้ว เราจะเลือกใช้งานอะไรได้บ้างนั้น ผมขอแยกเป็นแค่สองตัวคือ 1. Bigquery metastore และ 2. Bigquery Iceberg table
ผมมองว่าในอนาคตตัว Biglake metastore น่าจะค่อยๆหายไปดูจาก Document ของทางการแล้ว ยังบอกว่าให้ไปใช้ Bigquery metastore แทนเลย 😅

การเลือกใช้ว่าจะใช้ 1. Bigquery metastore หรือ 2. Bigquery Iceberg table ผมแบ่งง่ายๆแบบนี้
- Bigquery metastore – ถ้างานของคุณต้องใช้ Spark ในการ Ingest transform อยู่แล้วก็เหมาะเลย เพราะคุณจะไม่สามารถ Transform อะไรได้บน Bigquery เลย สามารถ Query ดูข้อมูลได้อย่างเดียว
- Bigquery Iceberg table – เหมาะสำหรับคนที่ไม่ได้อยากจะเปิด spark cluster แล้วมีการเขียน ผ่าน SQL อย่างเดียว และ อาจจะมีการใช้ Open source tool ในการเข้าไปอ่านข้อมูลใน GCS แต่ต้องระวังเรื่องการจัดการไฟล์โดยตรงเพราะอาจจะทำให้ข้อมูลที่แสดงบน Bigquery ผิดผลาดได้
Limitation ต่างใน Bigquery Metastore และ Bigquery Iceberg table
Limitations ต่างๆก็ไม่น้อยเลยทีเดียว เป็นข้อควรคิดให้ดีก่อนที่จะใช้ แต่ส่วนมากแล้วที่เป็น Limitation นั้น มักจะเป็นสิ่งเราจะไม่สามารถใช้ความสามารถของ Bigquery ได้อย่างเต็มที่ เช่น Meterialize table, time travel etc..
โดยในบทความนี้ผมจะยกมาแค่ตัวอย่างนะครับ เพราะมันเยอะมาก😅
Bigquery Metastore:
- ไม่รองรับ DDL or DML statements บน BigQuery engine
- Query performance for BigQuery metastore tables จาก BigQuery engine ช้ากว่าเมื่อเทียบกับ querying standard BigQuery table
- ดูต่อที่ https://cloud.google.com/bigquery/docs/about-bqms#limitations
Bigquery Iceberg table:
- Iceberg tables ไม่รองรับ renaming operations หรือ
ALTER TABLE RENAME TOstatements - Iceberg tables ไม่รองรับ materialized views.
- Iceberg tables ไม่รองรับ row-level security.
- ดูต่อที่ https://cloud.google.com/bigquery/docs/iceberg-tables#limitations
หวังว่าบทความนี้จะมีประโยชน์นะครับ🚀✨
REF:

Leave a comment