เกร็ด Spark – เกร็ดเล็กๆที่เกี่ยวกับ Spark
เปิดปีใหม่ด้วย Spark
หลายคนอย่างที่รู้อยู่แล้วว่างาน Big Data ยังไงก็หนีไม่พ้น Spark อยู่แล้ว
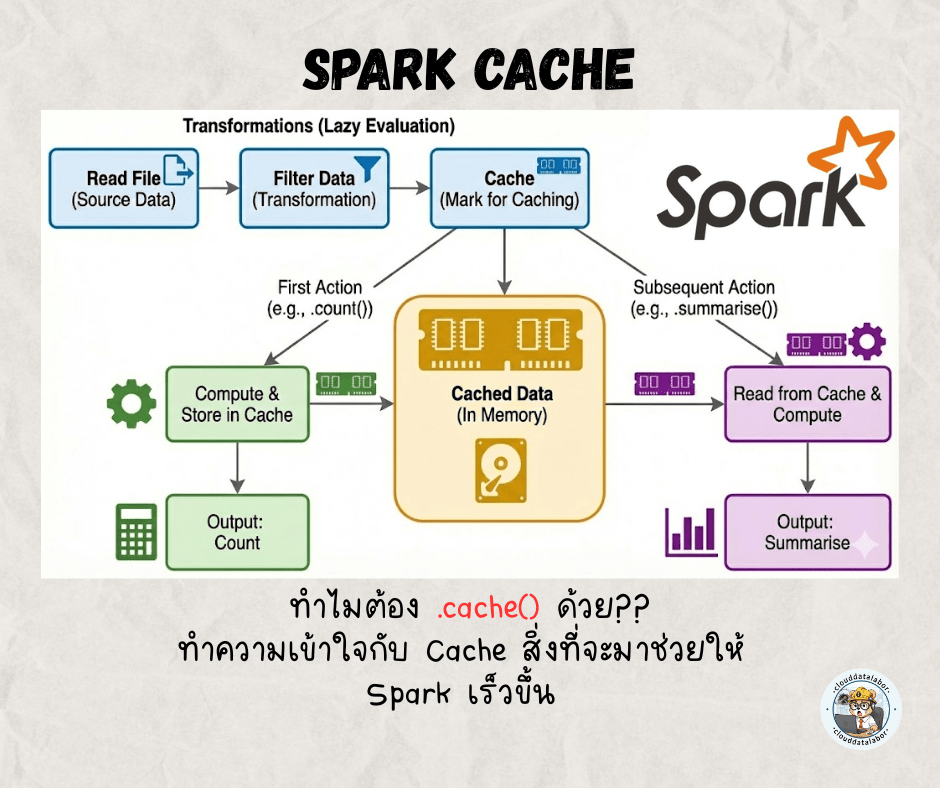
จึงอยากแนะนำให้รู้จักกับ Cache หรือ .cache() เป็นสิ่งที่ช่วยให้ประสิทธิภาพการทำงาน Spark ดีขึ้นได้ด้วย
แต่![]()
![]()
แอดอยากให้เข้าใจการทำงานของ Spark แบบไวๆ ก็คือ Spark นั้นมีรูปแบบการทำงานที่เรียกว่า Lazy evaluation ก็คือ Spark จะไม่ทำงาน (execute) ทันทีที่เรากำหนดค่าไป
.
เช่น
df = spark.read.parquet(”path/to/file/……..”)
#จะยังไม่ได้เกิดการอ่านไฟล์ทันที แต่ไปสร้าง DAG เอาไว้ก่อน (เอาไว้เล่าเกี่ยวกับ DAG อีกทีนะครับ)
แต่ถ้าเราใช้คำสั่งที่เป็นจำพวก action เช่น collect, count, saveAsTextFile หรือ show, Spark ถึงจะเริ่มทำงาน
df.show(5)
#ที่คำสั่งนี้ Spark ถึงจะเริ่มทำการอ่านไฟล์แล้วแสดงผลให้เราได้เห็นอย่างที่เห็นว่าการทำงานของ Spark เป็นแบบไหนไปแล้ว ที่นี้มาเข้าเรื่อง Cache กันดีกว่า ไม่งั้นไม่ได้เข้าหัวข้อกันสักที ฮา
อย่างที่เห็นว่า Spark จะทำงานเมื่อเกิด action เท่านั้น ตรงนี้เองก็เป็นจุดที่ทำให้ประสิทธิภาพการทำงานได้ช้าเช่นกัน โดยเฉพาะถ้า Dataframe เราต้องมีการเรียกใช้ซ้ำๆ
non cache เช่น
df = spark.read.parquet(”path/to/file/……..”).filter(F.col("value") > 0.5)
df.count() #อ่านไฟล์พร้อมกับ Aggregate ครั้งที่หนึ่ง
df.agg(F.sum("value")).collect() # Spark ก็จะอ่านไฟล์กับ Aggregate อีกรอบหนึ่ง เท่ากับว่ามีการทำซ้ำถึงสองครั้ง!!จึงแนะนำว่าถ้าเกิดเราต้องการเรียกใช้ซ้ำนั้น แนะนำให้พ่วง .cache() ไปด้วย
cache เช่น
df = spark.read.parquet(”path/to/file/……..”).filter(F.col("value") > 0.5).cache()
#จะยังไม่ทำงานทันทีตามรูปแบบของ Lazy evaluation
df.count()
#Spark จะทำงานแล้วก็จะเก็บข้อมูล df นี้ลงเป็น cache ที่ memory ทำให้การทำงานของ Spark ครั้งนี้อาจจะนานกว่าขั้นตอนแรกของ non cache เล็กน้อย
df.agg(F.sum("value")).collect()
#ตรงนี้จะไวขึ้นแบบเห็นได้ชัดแล้ว เพราะ Spark จะข้ามขั้นการอ่านไฟล์และfilterออกไป แล้วไปดึงข้อมูลที่ memory มาแทนเลยทำให้ไวกว่า non cacheข้อดีของการทำ cache
– ประสิทธิภาพที่เร็วขึ้นเมื่อมีการเรียกใช้ข้อมูลซ้ำ โดยเฉพาะครั้งที่สองเป็นต้นไป
ข้อระวังของการทำ cache
– อย่างที่รู้ว่า cache เก็บข้อมูลที่ memory ถ้าขนาด Dataframe เราใหญ่เกินไปอาจจะทำให้เกิดอาการ OOM (Out Of Memory)
ข้อแนะนำการใช้ cache
– เมื่อมีความต้องการเรียกใช้มากกว่าหนึ่งครั้ง
– ต้องระวังเรื่อง Dataframe ใหญ่เกินขนาด memory แนะนำว่าให้ใช้ .cache() หลัง filter() หรือหั่น Dataframe ให้เล็กลงสักนิด แล้วค่อยใช้ cache
– อย่าลืม![]()
![]() .unpersist() ทุกครั้งหลังจากใช้งาน cache เสร็จแล้วจะได้คืน memory กลับไปที่ cluster
.unpersist() ทุกครั้งหลังจากใช้งาน cache เสร็จแล้วจะได้คืน memory กลับไปที่ cluster
มาถึงตรงนี้ก็น่าจะพออธิบายเกี่ยวกับ Spark .cache() ให้ทุกคนพอเข้าใจได้บ้างแล้ว ในรูปอาจจะเขียน click bait หน่อยๆแต่อยากให้ระวังและเลือกใช้ให้ถูกต้องด้วยนะครับ
พยายามอยากอธิบายให้กระชับ ทำให้แอดอาจจะข้ามบางอย่างและไปเอาเฉพาะที่สำคัญมาเขียน เพราะงั้นถ้าสงสัยหรือไม่เข้าใจ หรือบทความผิดยังไง แนะนำและพูดคุยกันมาได้นะครับ
เอาไว้มาต่อกับ เกร็ด Spark กันใหม่ครับ

Leave a comment